
To download this article in pdf format Right Click Here.
At the end of this article if you have trouble viewing the Hebrew, the article is displayed in iframe format more friendly to Hebrew letters.
Codes in the Torah |
(The First 5 Books of the Hebrew Bible)
|
Reading with Equal Intervals
by Professor Daniel
Michelson
remain online.
edition of B’OR HA’TORAH and has been reprinted in a format, more appropriate
for the internet. B’OR HA’TORAH retains full rights to the information printed
in this article and if you wish to contact the publishers, SHAMIR, write to them
at 6 David Yallin Street, Jerusalem or call them at 5385702. When making an international call to Shamir, dial 972-2-5385702.
Introduction
| Daniel Michelson was born in Riga, Latvia, in 1949 to parents who survived the Holocaust. In 1971 he graduated in Mathematics from Moscow University and emigrated to Israel. From 1972-1980 he taught Mathematics at Tel Aviv University, studied toward a doctorate and served in the army. Upon completing his PhD thesis in Applied Mathematics in 1980, he did postdoctoral research at the University of California at Los Angeles. In 1983 he was awarded fellowships from the Alfred P. Sloan Foundation and from the Igal Alon Foundation. In the fall of 1983 Michelson returned to Israel and started to teach at the Hebrew University. There he learned about the codes in the Torah from his colleague and friend Dr. Eli Rips. This led him eventually, he says, “to do t’shuva”.Later he became involved in researching the Torah codes and lecturing about them (particularly in Los Angeles and Berkeley, California). Currently, Michelson is an Associate Professor of Mathematics at UCLA and at the Hebrew University. He lives now in Har Nof, Jerusalem, with his wife and three sons. [Information Update! Michelson now (Jewish Year 5762=2002) teaches at the |
What is Equal Interval Reading?Let us eliminate the spaces between the words of the Torah (the Five Let us make things more clear by showing a few examples. If we start Thus we find that the word תורה (Torah) is spelled out by 50-letter The number 50 has several important meanings in Judaism. Every fiftieth The above example is a part of a larger pattern found by Rabbi Michael
|

 The Letters of Deuteronomy Chapter 1:1 to Deuteronomy 1:8
The Letters of Deuteronomy Chapter 1:1 to Deuteronomy 1:8
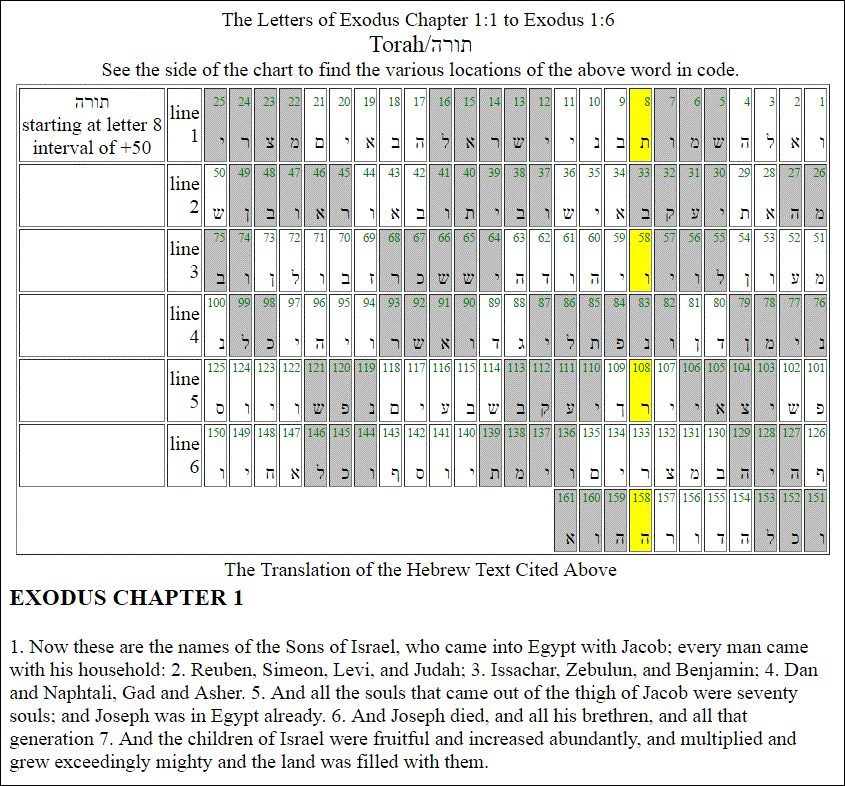
| ת | (4152), | ו | (8448), | ר | (4793), | ה | (6283) |
in the book. Indeed, תורה appears
three times in Genesis at the interval 50, which is what can reasonably be
expected from any book of such length and of similar concentration of the
letters ת,ו,ר,ה. There is however no reason why one of these three
appearances should start with the very first ת of the book and why this
should happen both in Genesis and Exodus. As a matter of fact, the
probability of such a coincidence is about one in three million!
The above is one of hundreds of patterns found in the Torah by Rabbi
Weismandel during World War Two. After his death in 1957 (~Jewish Year
5717), his students published a book entitled Torat Chemed that
showed just a handful of his findings. The rest of his findings were lost.
Of course at that time there were no computers. Instead, Rabbi
Weismandel’s deep knowledge of Torah guided him in deciding what and where
to seek.
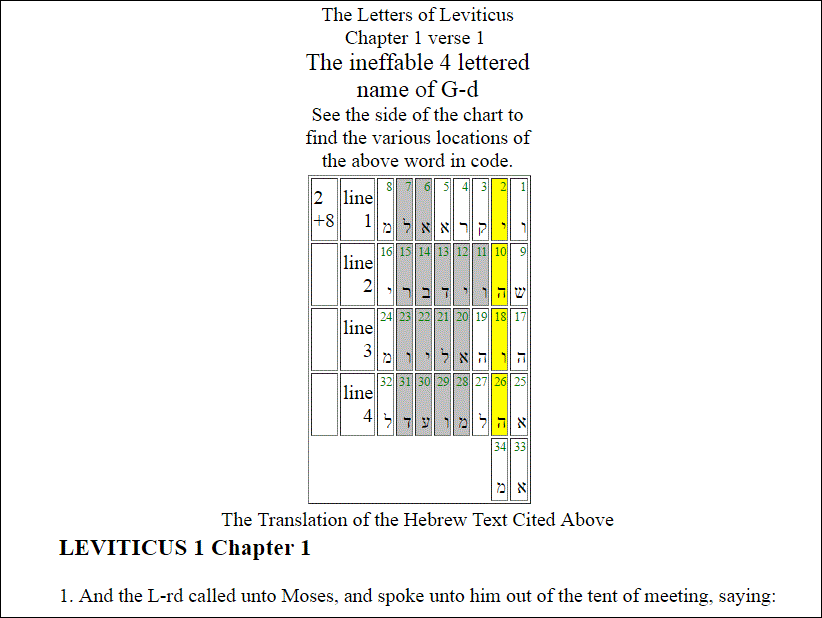
As for the length of the intervals-most of his examples use the numbers
50 or 26, the latter being the gematria of the ineffable four-letter name
of G-d (26=5+6+5+10 =י-ק-ו-ק). (The letter ק replaces the letter ה here so
as not to use the Name in vain.)
Later on, some of Rabbi Weismandel’s followers continued his search,
still working by hand. Rabbi Shmuel Yaniv and Avraham Oren and their
students should be mentioned here. But the real breakthrough occurred in
1982 when the computer was put to work in this direction. Here most of the
credit should be given to Dr Eli Rips of the Institute of Mathematics at
the Hebrew University in Jerusalem. Rips was joined by Dr. Moshe Katz of
the Haifa Technion and later by Doron Viztum of Jerusalem.
Let us make it clear. The computer does not have an intelligence to
find meaningful patterns. Instead, it is used as a fast and accurate
counting machine. The text under investigation is typed into the computer
and stored there as an electronic file. A set of instructions then tells
the computer to look for a certain word in the text at equal intervals in
a given range.
For example, find all appearances of the word ישראל (Israel) in the
first 10,000 letters of Genesis, at equal intervals ranging from -100 to
100. The computer then shows that the word is spelled out only twice, at
intervals of 7 and -50, and is located in verses 1:31-2:3 (The relevant
information is shown in Figure 2. Press here to display Figure 2 ).
These are
exactly the four verses that constitute the kiddush, which we
recite over a cup of wine every Friday night to sanctify the Sabbath. This
is astounding because seven and 50 are the only numbers related to
Shabbat. Seven stands for both the Seventh Day of Creation and the seventh
year of shmita when the land rests. After seven shmita cycles the
land rests also on the fiftieth year, the jubilee year.
Is this merely coincidence? A simple calculation shows that the
probability of the word ישראל appearing once at a given interval in the
above verses is about 1 in 1200. The chance of two appearances at the
intervals of 7 and 50 either backwards or forwards is about 1 in 400,000.
Another interesting example is shown in Figure 3, (Press here to display Figure 3 ). The text, Genesis 38,
tells the story of Yehuda and Tamar, who gave birth to Peretz and Zerach.
From the Book of Ruth we learn that Boaz was descended from Peretz. Boaz
married Ruth and had a son Oved, who had a son Yishai, the father of King
David. It is natural to ask, then, whether King David and his lineage are
hidden in the verses about Yehuda and Tamar. And indeed we do find the
names
| בעז, | רות, | עבד, | ישי, | and | דוד |
spelled out backwards at the same
interval of -49. Moreover, they all appear in chronological order! We have
already mentioned the importance of 49 being the seventh shmita, which is
followed by the jubilee year. The number 49 is also related to the
counting of the Omer, which starts on the second day of Pesach and ends a
day before Shavuot. Each day of the Omer is named according to the
descending order of the lower seven sfirot. The forty-ninth day of
the Omer is thus called Malchut sheb’Malchut (Kingdom of the
Kingdom). Could there be a name that better fits David, the king of kings?
Furthermore, Shavuot is the very day that David was born and died. It is
also the holiday on which the Book of Ruth is traditionally studied.
Could this example also be a coincidence? It is easy to estimate the
probability of such an event. After counting the total numbers of letters
in Genesis 38 and calculating the relative proportion in which each letter
of the alphabet appears in this total, we conclude that the probability of
בעז appearing in our chapter at a given interval is 0.02. (That is
assuming that on the level of equal intervals the text is random.)
Similarly, for the other four names the probabilities are 0.63, 0.65, 0.76
and 0.25. The odds for all five names to show, up at a given interval are
about 1 in 6500. If we also request that the names line up in
chronological order, the chances are reduced to 1 in 800,000. Now, if the
interval 49 is claimed to be as significant as -49, and as 50 and -50,
then these three possibilities would increase the chances to 1 in 200,000.
This is still quite an impressive number!
Let us turn to the third example in Figure 4 [Press here to display Figure 4 ] taken from the passage
about Jacob’s dream of the ladder reaching to heaven. When Jacob awoke
from his sleep he said, “Surely the L-rd is present in this place, and I
did not know it!” (Genesis 28:16). Where was this place? Rashi (the major
commentator on the Torah) writes that it was Mount Moriah where the Temple
later was built. Relying on the commentaries, Dr. Moshe Katz decided to
check for the word מקדש (Temple). Indeed, מקדש appears through the
important interval of -26, starting with the מ of the word מקום (Figure 4,
letter 33) in the above verse. However, if we continue to count at -26
intervals after theש of מקדש, we find another five-letter word, התורה (the
Torah) spelled forwards. Thus the two cornerstones of Judaism, התורה and
מקדש, are spelled as one continuous sequence of nine letters at an
interval of 26 (which is, to repeat, the numerical value of the
Tetragrammaton). The probability of such an event (for a fixed position of
the first מ ) is about 1 in 17 billion! In the same story we also find
ציון (Zion) and מקום (place) spelled out at 26-letter intervals. The next
example [Press here to display Figure 5] in Figure 5 (found by
Moshe Katz) is related to Joseph’s second dream in Genesis 37:9-10: “Here
I had another dream and here the sun and the moon and eleven stars are
bowing down to me”. On hearing this, Jacob asked his son, “What is this
dream you have dreamed? Are we to come, I and your mother and your
brothers, and bow low to you to the ground?” Rashi explains what Jacob
meant: “the mother [Rachel, represented by the moon in the dream] had
already died, and Jacob did not know that it referred to Bilhah [Rachel’s
maid] who raised Joseph as if she were his mother.” If we run on together
three of the words within Jacob’s rebuke,
| הבוא | חלמת | אשר |
we read within this string of letters
| מתה | רחל |
(Rachel is dead.)
Now let’s look for בלהה (Bilhah) in the same chapter. The computer
found two appearances of this word, both starting with the ב in the word
נבוא that comes directly after
| הבוא | חלמת | אשר | . |
One occurs at an interval of -99 and the
other at -156. We will not elaborate here on how the number 99 relates to
the matriarchy; however 156 is the gematria of
| Joseph’s name | יוסף | namely | ף=80 | ס=60 | ו=6 | י=10 |
| 80+60+6+10=156. |
There are hundreds of equally
impressive examples which, are not shown here due to the limited scope of
this review. However, on the basis of the material presented, we again
ask: are the above systems a mere coincidence or are they deliberately
planned? The skeptic must concede that the odds for each individual system
are very small. However, there are millions of different stories in which
we can look for these patterns, so that occasionally some of them occur at
small odds. Likewise in a lottery there are millions of players and a few
winners. The truth of the matter is that only three to four people have
been searching mainly the book of Genesis by computer for the last two
years. They explored perhaps a few thousand words and systems with an
astounding success ratio. Nevertheless, to counter the above argument on a
statistical basis we have to find story-independent phenomena, which can
be checked automatically by computer and compared with other texts. The
following example will be used to demonstrate such a general phenomenon.
This particular example is also important from a historical perspective
since it marks the beginning of the “computer era” in the Study of Torah.
A “Hidden” Aaron in Leviticus
Our story starts in 1982.
Avraham Oren of Kibbutz Sde Eliyahu was exploring the beginning of the
first chapter of Leviticus manually to find out if אהרן (Aaron) is spelled
out there at equal intervals. Why Aaron and why Leviticus? Leviticus
discusses mainly the work of the cohanim, the priests; and Aaron,
being the Cohen Gadol (High Priest) is the main hero of the book.
Nonetheless, in the first open chapter ( Parasha P’tucha ) of
Leviticus Aaron is not mentioned even once. Instead, the phrase “the sons
of Aaron” is repeated four times. Being familiar with the work of Rabbi
Weismandel, Oren naturally wondered if אהרן was hidden inside the chapter
in equal intervals. And indeed he found quite a few. When he showed his
findings to Dr. Eli Rips of the Hebrew University, the latter typed the
whole chapter on the computer and asked it to find all appearances of אהרן
therein.
The result of this search is shown in Figure 6. [Press here to display Figure 6.]
There are all
together 25 hidden “Aarons” not counting the explicit ones. The left side
of Figure 6 shows the location of the start of all the hidden Aarons
(namely the letter א of אהרן ) together with the equal length interval
that separates the first letter from the second, the second from the
third, and the third from the fourth. (As previously, negative numbers
mean counting backwards.) In this example we are not selecting a specific
meaningful interval like 26 or 50. Instead, the computer checks all
intervals from 2 to 235 (the maximum possible in this chapter) forwards
and backwards from every א, hunting the word אהרן.
When Rips received the results, he was overwhelmed by the large number
of total appearances: 25. In the 716-letter long section, containing the
first 13 sentences of Leviticus, there are
| 55 א’s, | 91 ה’s, | 55 ר’s | 47 נ’s. |
In a case of random distribution of these
letters in the chapter, a statistician would expect only eight appearances
of Aaron. Moreover, he would say that the probability of finding 25 or
more hidden “Aarons” is about 1 over 400,000. That means that 400,000
pages of text like the one in Figure 6 would have to be searched until 25
or more hidden ) אהרן ‘s would be found on one page.
A linguist could counter that the letters of biblical Hebrew are
correlated so that the language “likes” אהרן more than would be expected.
Notice, however, that 12 אהרן’s are going backwards, and it is not clear
why the “forward” language should like them. And if so, then it should
like other combinations of א,ה,ר,ן equally well. To check this, Rips took
all 12 possible combinations (there are 2x3x4=24, but forward and backward
count as one) and performed on them the same experiment as was done on the
word אהרן. In the lower part of Figure 7 we see the results of the
experiment. [Press here to display Figure 7.]
The meaningless
letter combination אהנר appears in the text 8 times, as does ארהן. The
other results of 9,7,5 and so on center around 8 with a deviation of ±3 in
a complete agreement with the statistics. Only אהרן stands out in contrast
to this agreement.
The next experiment is shown in the upper part of Figure 7. As is well known, in Hebrew there is a short
and a full spelling. Sometimes the same words are spelled fully and other
times in short form within the Torah. A change in the spelling would make
equal intervals non-equal. Thus there is no reason why the text should
prefer
| ן | n ← |
ר | n ← |
ה | n ← |
א |
over
| ן | n+y ← |
ר | n+x ← |
ה | n ← |
א |
So we fix the numbers x and y and let the
computer search for אהרן with all possible n (i.e. from 2 to 235). The
numbers x and y vary from -5 to 5 and for each pair x,y the total number
of אהרן’s is shown in the table. We see that these totals vary from 2 to
15 with an average of 7.3 and a standard deviation of 2.4. The number 25
corresponding to x=y=0 (i.e. equal intervals) is 7.4 standard deviations
away from the average! So indeed, our text “likes” Aaron at equal
intervals.
But what about other words? Maybe they exhibit the same phenomenon? And
what about other texts? For comparison Rips took all possible four-letter
combinations of the Hebrew alphabet. As there are 22 letters, the total
number of combinations, not distinguishing forward and backward spelling,
is 22x22x22x22/2=117,128. He took each possible “word” out of the 117,128
possibilities-say אבגד- and performed the same experiment on it as he did
on אהרן. Namely, he let the computer find the number of times that this
word appears in our chapter and compared the result with the statistically
expected number of appearances. Suppose that for אבגד these numbers are
correspondingly 5 and 3. Then he computed the probability of having 5 or
more appearances instead of the expected 3. The result was 0.185.
Now turn to the table in Figure 8.[Press here to display Figure 8.]
The vertical axis
shows the number of appearances of a word, while the horizontal axis shows
its probability (on a logarithmic scale). The number 232 in the sixth row,
third column shows that 232 words out of 117,128 appeared five times in
the text and the probability of them appearing that many times was about
1/10. Thus the word אבגד was counted among the 232. And similarly for the
other numbers. As the probability decreases and the number of appearances
increases, there are fewer and fewer words in the table. The position of
the word אהרן is shown by the circle. Obviously, Aaron is the winner of
the competition!
There is just one other “word”, יטעא (meaningless) with the same
probability of 1/500,000 which appeared six times. Actually: all
letter-combinations with a probability of less than 1/1000 turned out to
be meaningless. There are also 12 words which appeared more often than
אהרן but their probabilities are quite reasonable. Indeed, there are
letters that appear more frequently and less frequently in our text. Words
containing the more frequent letters should normally appear more often.
But what about other texts? For comparison, Rips took a fragment of the
same length (716 letters) from the beginning of the novel Hachnasat Kala
by Nobel Prize winning Israeli author Shai Agnon and ran the same
experiment on it for 117,128 words. We see on the second chart [Press here to display Figure 8b.] in Figure 8b that the
distribution of numbers is the same as above with only one exception – the
circle which contained אהרן is now empty! Here again, no meaningful word
passed a probability limit of 1/1000. This proves once again that the
entire phenomenon of אהרן has nothing to do with the Hebrew language.
Perhaps the comparison with Agnon is unfair since his is a different,
“modern” Hebrew. Ideally, a text should be chosen that is firstly canonic
and secondly very close to the Torah. Professor Ben-Chaim of the Academy
of the Hebrew Language came up with the excellent idea of using the
Samaritan Torah. The Samaritans are thought to be the descendants of
Kutim, the nations brought into Israel after the exile of the ten tribes
in the seventh century BCE. Although influenced by the Jewish religion,
they did not become part of the Jewish nation. There are still about 2000
Samaritans living in Nablus and Holon who possess a Torah different from
ours. Actually, there are a number of differences among their own
manuscripts, so it is hard to talk about an established Samaritan version.
Nonetheless, a few years ago two Samaritans, the brothers, Tzdaka,
published the most authentic version of the Samaritan text and compared it
with our Torah. [Press here to display Figure 9.] Figure 9 shows where in
the beginning of the book of Leviticus, our text of the Torah differs in
spelling and in wording from the Samaritan text.
The “Aaron section” discussed above consists of the first 13 verses.
(The differences between the two texts however, have been presented in
Figure 9 up to verse 17.) In addition to an extra 20-letter phrase
inserted into the tenth verse of the Samaritan text, there are 17 other
points of difference (in the first thirteen verses). Otherwise, both texts
tell the same story and in translation would read the same. So it was very
interesting to see what effect these differences had on אהרן. And lo and
behold, they destroyed 22 out of the 25 hidden “Aarons”! However, seven
new “Aarons” surfaced. Thus the total became 10 instead of 25-in complete
agreement with the statistics since the expected number is about 8 with a
deviation of plus or minus 3.
At this point the skeptic is ready to admit that people could have done
it deliberately. “You know,” he says, “they had a lot of time to do this.
The sages say that Rabbi Akiva used to count the letters of the Torah. So
apparently there was such a tradition.”
Let us explore this line of thought. Suppose somebody, say some of the
priests themselves, planted these “Aarons” into the text. But for what
purpose? To impress later generations? Until discovered by Avraham Oren
and Eli Rips, this secret was absolutely unknown. Moreover, had it been
discovered 40 years ago, nobody would have been impressed by it. Indeed,
we must make all the comparisons to realize how extraordinary this
phenomenon is; and it was impossible to do this before the advent of the
computer. So our skeptic backs up and suggests that maybe the whole system
of the “Aarons” is just another coincidence. “After all, why did you take
the first chapter and why Aaron? There are so many chapters and so many
important words you could have chosen so that even one success with a
ratio of 1/400,000 is not at all remarkable!” We reply that Aaron is the
most important word in Leviticus and intuitively the first chapter has
preference over the other ones. However, the whole story of the “Aarons”
was brought here not with the intention of showing another oddity but with
the intention of demonstrating some general phenomena.
The Clustering Effect
After discovering the “Aarons”, Rips obtained an electronic text of
Genesis and started a systematic investigation. (The full electronic
error-free text of the Torah became available to us only recently.) By the
text of the Torah, unless stated otherwise, we always mean the traditional
Ashkenazi Masoretic text published by Koren in Jerusalem. There is another
text accepted among Yemenite Jews. These two versions were carried by two
independent traditions for more than a thousand years. Yet, as we compare
these texts, they differ only by 9 letters out of 304,805! Three of these
nine appear in Genesis (which totals 78,064 letters). Further comparison
may be sought in the various existent ancient manuscripts, for instance
the 1,000 year-old Leningrad Codex written in Egypt (and named after the
library that possesses it). As was shown recently by Dr. Mordechai Breuer
in Keter Aram Tzova, this text differs from the Koren edition by
130 letters. Almost all of these 130 letters are contradicted by the
majority of other manuscripts and, most important, by the Masoretic
instructions. Nonetheless the Leningrad Codex is considered the
“scientific text” of the Torah and is used by several universities for
their databases. Clearly, even one missing or extra letter destroys the
hidden words, which “leap” over it. However, the examples shown in this
review appear in parts of Genesis not containing any of these contested
letters and hence are not affected by them.
Let us now define the clustering effect. As we saw with “Aaron”, the
word was spelled explicitly (four times) in the same chapter where it
appeared in a large concentration in equal interval form. Rips wanted to
check whether the same phenomenon occurs with other words. Since it was
not feasible to scan all the words, Rips started with the words at the
beginning of Genesis.[Press here to display Figure 10.] The text in Figure 10
consists of Genesis chapter 1 and 2 and Genesis 3 verse 1 as they appear
in the Koren edition. The first 2956 letters (i.e. Genesis chapter1,2 and
part of Genesis 3:1) have about 120 different words longer than two
letters (not counting different grammatical forms). Each word was run by
the computer to find where it appears at equal intervals. The intervals n
were taken in a range from 2 to some N, both positive and negative.
The results of such a search for the word עדן (Eden) are shown in Figure 10. The word עדן is spelled out explicitly in
three places as shown by the words highlighted in yellow. The red
asterisks show the hidden “Edens” and the numbers at the left side of the
chart indicate where the ע of עדן is located and the appropriate intervals
between that letter and the next letter of the word.
The range of intervals N was taken to be 120. The number N is chosen in
such a way that there is a reasonable amount of hidden words. So then, if
one chooses N=240 there would be twice as many hidden “Edens” sprawling
over the text and it would be difficult to see the clustering. Likewise
for N=60 it would be too few words to make statistical estimates. We see
that there are eight hidden “Edens” within the first 1815 letters of
Genesis (Genesis 1:1- Genesis 2:3). The story of the Garden of Eden is
told starting in the verse Genesis 2:4 starting at letter 1816. Here
inside a segment of 379 letters 16 hidden “Edens” appear? What force has
drawn them together? Maybe the three explicit “Edens” increase the local
density of the letters ד ,ע , and ן so that there are more chances for the
hidden ones? A computation like the one performed for Aaron shows that the
expected number of “Edens” is about 5 and the probability of such a
deviation is about 1 in 10,000. (We see another weaker cluster close to
the end of Figure 10 where the Torah narrates the creation of woman.)
[Press here to display Figure 11.] In Figure 11 there is
a similar example with the word הנהר (the river). The word is mentioned
four times explicitly as shown by the words highlighted in yellow. When
run on the computer with intervals up to 80, it produces a cluster of 11
words that start within lines 76 to 101, while on a usual range of even
40 lines it appears about three times. [ Figure 11 has
been divided up into 120 lines ].
[Press here to display Figure 12.] Next in Figure 12 the
word מקוה (gathering of water) is exhibited. There is a cluster of ten
words around the explicit מקוה in the first 40 lines of Figure 12 while in
the other two 40 line segments, in Figure 12, the word appears once or
twice. Note that this time the hidden words do not cross over the explicit
one so that the letters of the explicit מקוה could not cause the cluster.
[Press here to display Figure 13.] Figure 13 demonstrates
a similar effect with the word מקום surrounded by a cluster of eight
hidden words, while in the second and third segments of 40 lines, there
are all together four hidden words.
The results for long words are especially interesting. Obviously, the
longer a word is, the smaller are its chances to be found in a text at a
given interval. [Press here to display Figure 14.] In Figure 14 three
such words are shown: בהבראם (as they were created), החוילה (the Havila
[river]) and המועדים (the appointed times). The six-letter word בהבראם was
searched for by the computer over the whole book of Genesis (i.e. 78,064
letters) at equal intervals ranging from -300 to 300. It was found four
times. At the interval 176, it clusters around the explicit word.
Similarly, the word החוילה in the same range appears six times and
clusters around the explicit word at the interval of 167. The seven-letter
word המועדים was searched for in the book of Genesis at intervals from
-10,000 to 10,000 ! It appeared only once, at the interval of 70,
clustering exactly where the word is spelled explicitly. (By the way,
there are 70 specially appointed times for holy days called מועדים in a
year, as defined in Leviticus 23: fifty-two Sabbaths, seven days of
Pesach, one day of Shavuot, one day of Rosh Hashana, one day of Yom
Kippur, seven days of Sukkot and one day of Shmini Atzeret.)
But what about other words? Obviously, we cannot show here all of the
results. However, about 40% of the words in the above three pages produced
a strong clustering effect. Another 40% showed a moderate clustering. And
the rest-no clustering. Part of the clustering is effected by the non-even
distribution of letters. For example, when the word אדם (Adam) is
mentioned in Genesis 2:5,7 the word אדמה (earth) appears nearby, adding
the letters ם,ד,א to the text, thus increasing the likelihood of finding a
hidden אדם. When we took a 3OOO-letter piece of text from Chaim Nachman
Bialik’s Hebrew novel Arie Ba ‘al Guf, there was also a cluster
effect although much weaker than in Genesis. Hence, in order to measure
the “net” clustering, Rips suggested comparing the equal intervals with
the non-equal ones in the same text, as was done with “Aaron” (see Figure 7.)
The next question is how to measure the clustering quantitatively. The
simplest way is to specify in advance a neighborhood of the explicit word
and then check how many hidden words appear in this neighborhood. It is
clear, however, that for longer words the neighborhoods should be greater
than for the shorter ones, and hence it is preferable not to compare words
of different lengths. Finally, a controlled experiment was run for all
three-letter nouns in Genesis 1 and 2, all together 50 words. The
neighborhoods to be considered were 300 letters long (about eight lines)
and centered on the explicit words. The total number of hidden words in
these neighborhoods was 370 versus the expected 300, which was four
standard deviations away from the expectation. The results for non-equal
intervals were about the average.
Next the same experiment was performed on the Samaritan version. Here
the results for the equal and non-equal intervals were about the same as
the expectation.
Four standard deviations correspond to the probability of about
1/10,000. This is indeed a very small number. However, some statisticians
may say that the text under investigation is too short. Besides, for
three-letter words the non-equal interval test is very limited. That is,
for the word עדן we consider the sequences
| ן | n+x ← |
ד | n ← |
ע |
with fixed x and all
possible n. The number x should be small so that the non-equal intervals
would be a small perturbation of the equal ones. For example, if x varies
between -5 and 5 we have only ten different results to compare. If the
word is longer, e.g. a five-letter word אבגדה the perturbed sequences are
| ה | n+z ← |
ד | n+y ← |
ג | n+x ← |
ב | n ← |
א |
so that with x,y,z in
the same range of -5 to 5 there is a sample of 1330 different results.
Hence Rips suggested checking the clustering for five-letter words over
the whole book of Genesis.This requires a prohibitive amount of
computations, so Rips restricted himself to all four-letter nouns preceded
by the definite article ה encountered in Genesis. The final list consisted
of 86 words. Next Rips defined a probability function, which measured the
clustering for each word. The definition is too technical to be presented
here. Roughly speaking, the function attains the values between 0 and 1,
is uniform for a random text and becomes small when a hidden word with a
short interval appears close to the explicit one. Then for each word a
“race” was performed in which the equal intervals competed with the
non-equal perturbations. In the first “race” the numbers x,y,z were
between -2 and 2, thus providing 5x5x5=125 “runners”. The probability
function was measured and the “runners” with the smallest value would win.
The results of the 86 “races” are as follows. In three instances the
equal intervals defeated the non-equal ones. The words were המקנה (the
livestock), החתמת (the seal) and הבהמה (the domestic animals). For 11 more
words the equal intervals were among the top 10% of the “runners. These
results are not impressive at all since the probability that 14 out of 86
instances would be in the upper 10% is about 1/20. Next, the three winners
were “allowed” to compete with about 5000 “runners”. Namely, the range of
x,y, and z in the non-equal intervals was increased from [-2,2] to [-8,8]
which produced 17x17x17=4913 “competitors”. (It was too expensive to make
such a “race” for all the words since it takes several hours of computer
time to run a single word.) The words המקנה and החתמת were champions also
in the big race. Now the combined phenomena of the 14 top 10% words and
the two top .02% ones have a probability of 1 over 30,000.
The same experiment was performed also on the Samaritan text. Here only
two words הקדשה (the harlot) and המגדל (the tower) -were in the top 10%
and no word entered the upper 1%, Thus the Samaritan text behaves like a
“normal” one.
Our skeptic might be unimpressed by the probability of 1/30,000.
Indeed, with the “Aarons” we already had 1/400,000. However, this time,
the test was both word and segment independent, Namely, instead of a
specific (though important) word like Aaron, we took a big “natural”
sample and instead of the first chapter-the whole book of Genesis. One
also should bear in mind that clustering is only one aspect of the
infinite information hidden in the Torah through equal intervals. There is
no clustering for “Torah” in Figure 1 or for “Israel” in Figure 2. King
David is not mentioned explicitly in Figure 3 so we lose another story and
likewise for the “Temple” in Figure 4 and “Bilhah” in Figure 5. It is
quite amazing that after all nontrivial patterns have been neglected there
is still something to observe.
In the next section we will demonstrate another general idea, which is
common to many words and patterns.
The Minimum Intervals
When the computer searches for a certain word at equal intervals of
numbers, it will find the word many times. Some of the intervals may be of
special interest like the numbers 50 and 26; but what shall we do with the
other ones? In the course of numerous experiments Rips observed that the
short intervals tend to be more significant than the long ones; they
appear more often in relevant places. We will present here one example of
this phenomenon. [Press here to display Figure 15.] The text in Figure 15
consists of Genesis chapter 2 and the first three verses of chapter 3.
Verse 9 reads: “And from the earth G-d caused to grow every tree that
was pleasing to the sight and good for food, and the tree of life in the
middle of the garden and the tree of knowledge of good and evil.”
As the names of the trees are not mentioned explicitly in this chapter,
Rips suggested that perhaps they are hidden there at equal intervals. He
took all the 25 trees named in the Torah (as listed in The Fauna and Flora
of the Torah by Yehuda Feliks) and found them in the above chapter! Before
the reader jumps out of his seat, let us explain that three- or
four-letter words would normally appear at some intervals in a segment as
long as ours (about 1000 letters). What is so exceptional here is that
most of the intervals (except for ערמן and לבנה) are very short. There is
no other segment in Genesis of such length, which contains so many trees
at intervals less than 20. Based on the density of the letters in the
chapter, one could estimate the probability of this “orchard” phenomenon.
It comes to about 1 in 100,000!
Conclusion
We started with the “Torah of Rabbi Weismandel, went through the
examples of “Israel”, “King David”, “Temple-Torah”, “Rachel with Bilhah”,
to “Aaron”, then to the clustering effect in general and to the “orchard”
and the minimum intervals phenomenon. There are many more fascinating
examples and stories, which could not be included in this limited review.
A book with much of this material is expected to be published in Israel
soon. We hope that our skeptic concedes that the equal interval phenomenon
is not deliberate computer trickery but a reflection of a hidden design.
We are far from understanding the rules of this design, in particular from
understanding what stands behind the numerical values of all the different
intervals.
In recent years some other coded systems were discovered (or
rediscovered) in the Torah. Among others is the “multiples of seven”
pattern of key words in each chapter appearing 7, 14, 21… times. Another
rule discovered by the late Rabbi Suleiman Sasson states that every word
which is repeated in Torah more than 80 times, appears for the eightieth
time in a segment of text discussing a promise, covenant, marriage or
purchase (i.e. different types of contracts). The equal intervals system
is distinct from systems such as these in that it functions on the letter
rather than on the word level and it contains apparently limitless
information.
But who made this design? Midrash Tanchuma says Moses saw the Torah as
a string of letters of black fire on white fire. This string of letters
was not divided into words. As G-d dictated the Torah to him, Moses wrote
it accordingly in the form of words and chapters. As Maimonides states in
the introduction to his Mishneh Torah, Moses wrote out a copy of the Torah
before his death for each tribe plus one to be kept in the Ark. Jews
believe that the modern Torah text is the exact copy of the original
(except perhaps a few letters, as suggested by comparing the Yemenite and
Ashkenazi texts).
How does this affect biblical criticism? According to the theory of
biblical criticism, the Torah is a patchwork of pieces written at
different times by different authors. The pieces allegedly were put
together during or after the Babylonian exile and then canonized. For
example, Bible critics contend that Genesis 1 and Genesis 2 were written
by different authors because Genesis 1 uses the name אלקים for G-d while
Genesis 2 uses the Tetragrammaton. Hidden words like בהבראם which connect
the first two chapters of Genesis then would have to be assumed by the
critics as inserts made by the final “editor”. When we counted the trees
in Figure 15 and the most outstanding clusters like “Eden”, ‘the river”
(Figures 10 and 11) and a few other systems with probabilities less than 1
out of 1000, we found that the number of letters employed by the hidden
words is about 30% of the total. Should we then be forced to believe that
this “editor” created all these codes with some small modification-and
without any apparent reason?
“It is possible,” says our skeptic, “that the ancients possessed some
secret knowledge which we cannot comprehend. Take, for example, the great
pyramids or the Inca temples.” Whatever they knew, nobody would suggest
that they could foresee the future (unless they had a time machine).
Having commenced this article with an example of Rabbi Weismandel, let
us conclude it with another example of his. The example concretizes the
parallel between Moshe Rabbenu (Moses our Teacher) and Rabbenu Moshe ben
Maimon (known also as Maimonides and as Rambam, his Hebrew acronym). The
Rambam was born in Spain 852 years ago and later settled in Egypt, where
he became a court doctor of Tzalach Ed-Din, There he wrote his most
important work, the 14-volumed Mishneh Torah which classifies and
clarifies all of the 613 Commandments. [Press here to display Figure 16.] Figure 16 shows the
beginning of the Mishneh Torah where Maimonides explains the origin of the
Commandments and how they are classified in his 14 books.
In addition to having the same name, both Moshe Rabbenu and Moshe ben
Maimon lived in Egypt and performed marvels before its rulers.
(Maimonides’s marvels were performed in his capacity as court doctor.)
Furthermore, Maimonides’s Mishneh Torah parallels Moshe Rabbenu’s own
Mishneh Torah, i.e. the book of Deuteronomy, which summarizes the entire
Torah. (See the first example given in this article on the word “Torah”
appearing at a 49-letter interval in Deuteronomy for an explanation of how
this book differs from the others in the Five Books of Moses.)
The following finding is attributed to Nachmanides (the Ramban) who
lived a few decades after Maimonides. The phrase
| מצרים | בארץ | מופתי | רבות |
(Rabot Moftai B’eretz Mitzrayim-“My
marvels may be multiplied in the land of Egypt”) in Exodus 11:9 implies
Maimonides. Indeed the first letters of the above four words form the word
| רמבם | (RaMBaM). | [Reminder! the letter מ when it appears at the end of a word looks like this ם ] |
[Press here to display the Rambam and Mishneh Torah
Code.]
“How beautiful,” says our skeptic. “but you probably will find a
‘Rambam’ on every page.” So we checked it out and found that this is the
only “Rambam” acronym in the entire Torah.
But that’s not the end of the story. Forty years ago when Rabbi
Weismandel came across this passage, he asked himself whether some
additional information about the Rambam was hidden in this passage at
equal intervals. So he took the title of Rambam’s MishnehTorah,
spelled in Hebrew משנה תורה and searched for it. Since he had already
discovered the “Torah” system at 50-letter intervals (corresponding to 50
gates of wisdom), he tried 50 again. And indeed, starting with the מ of
Moshe in the verse just quoted, he found the word משנה at a 50-letter
interval. The second word of the title תורה appeared much further on in
the text at a 50-letter interval. The large gap the appearance of משנה and
תורה apparently puzzled him, so he counted the letters between them. They
came to 613. (This is the very number of Commandments in the Torah which
were summarized by the Rambam in his Mishneh Torah! Read the introduction
to his book in Figure 16. )
If you still wish to know the probabilities-the likelihood or such a
משנה תורה starting with a given מ is 1 in 186,000,000. You could of course
try some other מ, say 10 possibilities for מ in a neighborhood close to
the “Rambam”, And you could play with 613, counting between the ה of משנה
and the ת of Torah or the מ of משנה and the ה of תורה and also include or
exclude the first and the last letters in the counting, giving you six
possibilities. With all this playing around, you can increase the
likelihood to 1 in 3 million.
Now, what is the bottom line? Either the author of the Torah knew 2500
years in advance about Maimonides and the Mishneh Torah or the whole story
is another coincidence with a probability of 1/3,000,000.
Unfortunately, when it comes to very small or large numbers, people
often lose common sense. Let us suggest the following mental experiment.
The opportunity is offered to play Russian roulette when one of six
chambers of a pistol is loaded with a bullet. After the cylinder is
rotated, one shoots the pistol at one’s head. There is no other partner,
and one must repeat the game 81 times. If the person dies-he dies. If he
stays alive (and the chances are 1 in 3,000,000) he will have an exciting
experience. Would our skeptic take the offer? Three thousand three hundred
years ago there was another skeptic – Pharoah of Egypt. Our story from
Exodus 11-12 is narrated after Pharaoh has already experienced nine
plagues. He still was not convinced because, as the Torah says, “The L-rd
hardened the heart of Pharoah.” Should one wait for the tenth plague?
© 2002 [ 5762 in the Jewish Calendar] All Rights Reserved.